In brief
- Machine learning operations (MLOps) is a core part of machine learning engineering, helping to streamline the way that machine learning models are taken to production, maintained and monitored
- Applying these practices increases the quality, simplifies the management process, and automates the deployment of machine learning models in large-scale production environments
- This article describes the way we introduced MLOps to a trading bot development project and how this helped to control the models
As your team grows, the processes become more complex. In this article, we will talk about the interaction of a large system of neural networks for a trading bot project and the MLOps system, you might start thinking about MLOps technologies and how they can help increase control over development. If talking about our team, at some point we began to feel that we were lacking MLOps practices, so we decided to explore new tools and options.
To master these, we chose one of our projects — a trading bot with several types of models, some of these models have various versions. Without MLOps, controlling the models might be a challenging task, so this project is of high priority for us.
In this article, we will describe how we translated our trading bot to the Vertex AI platform from Google.
About the project
Most algorithms for analyzing stock price behavior are based only on the historical price, but it is also important to consider the impact of company news. Therefore, our main idea was to create a system that could predict the price not only according to a schedule, but also according to text news.
The main idea of the algorithm was to combine the company news, the stock price and technical analysis. This requires 3 machine learning models:
- Language model — it evaluates the news. This estimate is the model’s confidence that the price will rise by a certain threshold.
- The model for time series processing also converts the price chart and technical analysis into confidence.
- The final classifier takes an average estimate of the news for the current day as input, their number and the confidence of the model for time series.

Thus, we have a system that gives predictions both on the text and the price chart.
Language model
As the foundation of the language model, we chose the GPT-2 transformer. This model was introduced by OpenAI in early 2019. The model was previously trained on a WebText dataset consisting of 45 million links to websites.
GPT-2 converts the text at the input into a special matrix that contains a contextual representation of words. Next, this matrix is transformed using a single linear layer into a binary classification.
The resulting language model is universal for all companies.
Price model
Recurrent networks are best suited as the basic network architecture for working with stock prices. The main advantage of recurrent networks is the ability to remember long-term dependencies. There are many implementations of this architecture, but the long short-term memory (LSTM) network is considered one of the best in terms of operational quality. The developed network consists of several LSTM blocks and subsequent data transformation.
A vector from the historical price and several technical analysis indicators are fed to the input at each moment in time. The output of the last cell is fed into a neural network consisting of four layers. As a result, we have three numbers corresponding to the confidence of the model to buy, hold or sell the stock.
Final classifier
As the final classifier, we use a random forest. This model belongs to the algorithms of classical machine learning and consists of several decision trees that determine, by majority vote, whether the price will rise.
Testing
To test the algorithm, we decided to implement a trading strategy for it. To do this, we compiled a portfolio of several shares and selected the maximum fraction of one share when buying. After that, we performed back-testing, that is, the launch of a trading strategy based on historical data.
The following table shows the test results. The graph shows the account balance over time.


As a result of testing the trading strategy, we obtained positive results (most of the transactions are positive, the drawdown is less than 1%, the average profit of the transaction is 1.8%).
We were rather pleased with the results thus far. We do, however, need to dive a little deeper into the world of MLOps to demonstrate how this was able to help us and how Vertex AI is ready for ML.
MLOps
MLOps is an ML engineering culture and practice that aims at unifying ML system development (Dev) and ML system operation (Ops). Practicing MLOps means that you advocate for automation and monitoring at all steps of ML system construction, including integration, testing, releasing, deployment and infrastructure management.

Below is a classic diagram from a Google article which shows that only a small part of the real ML system is contained in the ML code. The necessary elements surrounding it are extensive and complex.
On this diagram, the rest of the system consists of configurations, automations, data collection, verification, testing, debugging, resource management, model analysis, metadata management, model serving and monitoring.

The automation level of these processes determines the maturity level of your ML project, which reflects the speed of models learning on new data, or the speed of learning taking into account other implementations. Next, we will describe two levels of MLOps, starting with the most common one — which does not require automation, and then we will switch to the full automation of ML and CI/CD pipelines.
MLOps level 0: Manual process
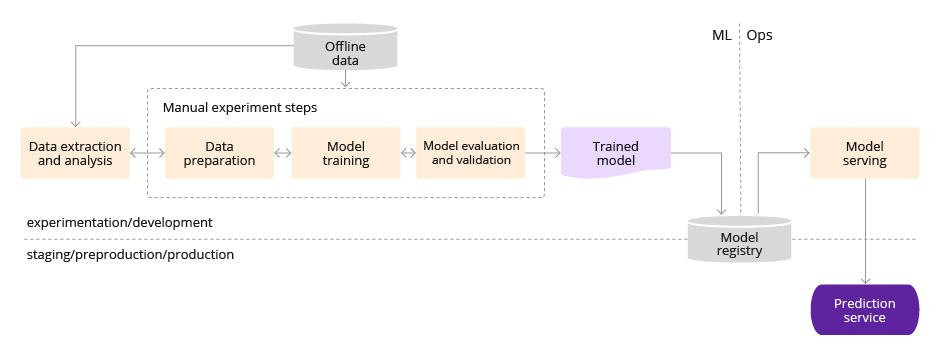
The following list of characteristics reflects the MLOps level 0 setup:
- Manual, scripted interactive process. Each of the standard steps is performed manually; manual code execution, and manual data exchange between the steps are required
- Disconnect between ML and operations. The process divides data scientists who develop models and the engineers serving them. DS passes the model in the form of an artifact to the team of engineers
- Infrequent release iterations. The process assumes that the data scientist team manages a certain number of models, while the frequency of their updates is not very clear
- No CI. Since there are supposed to be some changes in the implementation, CI is ignored. Usually, code testing runs using laptops or some scripts
- No CD. Since there is no versioned deployment of models, CD is ignored
- Deployment refers to a prediction service. This process only concerns the deployment of a trained model as a “prediction service”, it can be a microservice with a REST API, for example, and not an ML system deployment
- Lack of active performance monitoring. The process does not analyze the model operation, which is required to track model degradation
MLOps Level 1
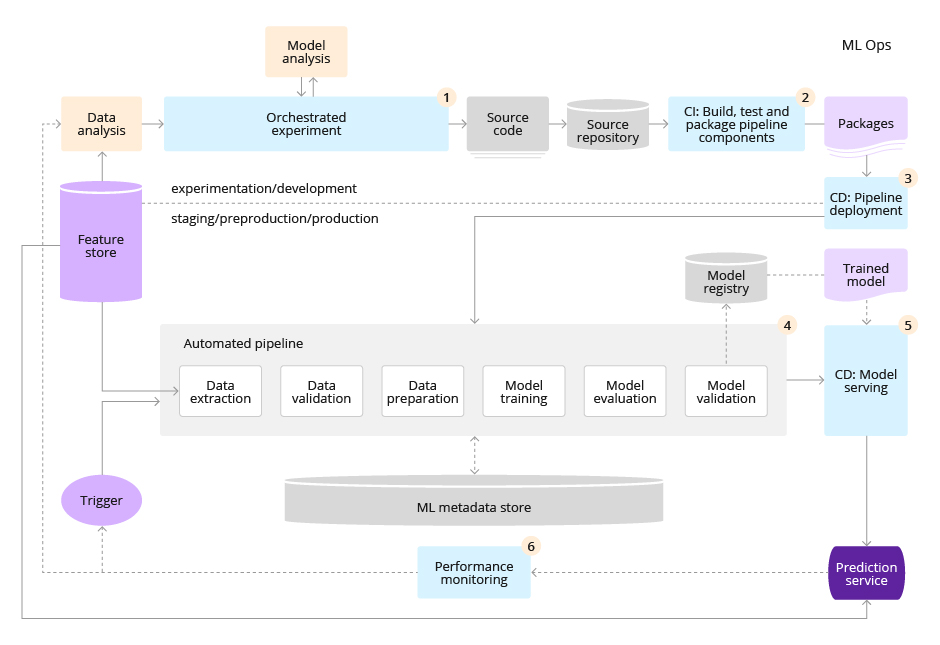
The following list highlights characteristics of the Level 1 setup:
- Quick experiments. The steps of the ML experiment process are consistent. Transitions between steps are automated
- Model CT to production. The model is automatically trained in the production environment using up-to-date data and pipeline triggers
- Experimental-operational symmetry. This is a pipeline implementation that is used in the development or experimental environment and in the preparation and production environment, which is a key aspect of MLOps practice for the unification of DevOps
- Modular code for components and pipelines. To build ML pipelines, components must be reusable, composable and potentially shared in ML pipelines. In addition, ideally, components should be placed in containers to perform the following tasks:
- Decouple the execution environment from the custom code runtime
- Make code reproducible between development and production environments
- Isolate each component in the pipeline. Components can have their own version of the runtime environment and have different languages and libraries
- Apply models CD. The ML pipeline is continuously delivered to the production inference server and trained on new data. This is a deployment step when the validated models move to the step of serving models and creating inference services
- Pipeline deployment. At level 0, you have deployed the model as an inference server. Level 1 implies the deployment of the entire training pipeline, which is automatically and recursively run, while serving trained and validated models as a prediction service
Vertex AI
The main feature of the new platform is its scale and integration with Google Cloud. Vertex AI has all Google cloud tools incorporated for preparing datasets and training ML models.

According to Google developers, teams will be able to completely transfer all ML processes to Vertex AI: Data engineers search for data in Google BigQuery, annotators mark-up data using built-in tools, data scientists configure learning algorithms in AutoML and automatically select optimal hyperparameters. A trained and tested ML model can be connected to a working application in a couple of clicks — either uploaded to a specially prepared server in Google Cloud or exported to one of the popular formats.
Despite the comprehensiveness of the platform, developers have provided with the possibility to replace any part of it with their own solutions. Support of Docker containers allows the writing code in any programming language and use of any libraries. Client bindings for Python, Java and Node.js are officially supported. Containers are not limited to anything in particular, they have access to the Internet and Google Storage, which allows the downloading of any data necessary for training the model. A similar mechanism also works for the code of the ML model itself, which can be created using an arbitrary technology, packed into a container and loaded onto Vertex AI.
Initial setup
1. In the Google Cloud console, on the project selector page, select or create a Google Cloud project. Make sure that billing is enabled for your Cloud project.
2. Enable the Vertex AI API.
3. Install the gcloud CLI. For Linux, run the following commands:
curl -O https://dl.google.com/dl/cloudsdk/channels/rapid/downloads/google-cloud-cli-402.0.0-linux-x86_64.tar.gz tar -xf google-cloud-cli-402.0.0-linux-x86_64.tar.gz ./google-cloud-sdk/install.sh
4. Open a new terminal so that the changes take effect.
./google-cloud-sdk/bin/gcloud init gcloud components update && gcloud components install beta gcloud auth login
For other platforms, use this: official documentation.
5. Install Python SDK:
pip3 install --upgrade google-cloud-aiplatform google-cloud-storage jsonlines -q
You will also need to authorize Docker to upload our images.
1. Enable the Container Registry API.
2. Open the terminal and run:
gcloud auth configure-docker
Let’s create a bucket in Cloud Storage for storing datasets and training artifacts. It is better to create a name using the projectname-bucketname approach. For example, in the gems-ai-ml project, we will create a new bucket gems-ai-ml-vertex-bucket. We will use the us-central1 region in all cases.
Adding datasets
For initial tests, you can add a dataset manually via the Cloud Storage interface or via the Python SDK.
Consider adding datasets via Cloud Storage:
1. Open a page with the created Buckets.
2. Select the necessary Bucket.
3. Upload a file with a dataset.
Also consider downloading using the Python SDK:
from google.cloud import storage
storage_client = storage.Client()
bucket = storage_client.bucket(bucket_name) # e.g. bucket_name = “gems-ai-ml-vertex-bucket”
blob = bucket.blob(f"{bucket_name}/{output_filename}") # e.g. output_filename = “dataset.csv”
blob.upload_from_filename(local_path_to _dataset) In order not to manually download data every time anew, we should create a script that takes data from the necessary source using the code from the example in the Python SDK, and then puts it in the Storage Bucket.
You can also create a Dataset entity in Vertex AI on the Datasets tab. This entity is necessary to train the AutoML model, but since we will use custom training, creating a Dataset is not required.
Custom training
Custom training will be performed inside the Docker container. To do this, you must first prepare the training code of the model. Here are the features of the code for learning in Vertex AI:
1. Get command line arguments for training configuration:
def get_args():
parser = argparse.ArgumentParser()
parser.add_argument(
'--model-name',
default="gpt_linear_full",
help='The name of your saved model')
parser.add_argument(
'--model_dir',
help='Directory to output model and artifacts',
type=str,
parser.add_argument('--data-uri', type=str, default='bert_main_dataset_11k_news.csv', help="Dataset path or gcp uri")
parser.add_argument("--mode", default='stocks_news', type=str, help="train or stocks_news.")
parser.add_argument("--num-epochs", default=N_EPOCHS, type=int, help="num epochs")
parser.add_argument("--batch", default=BATCHSIZE, type=int, help="batch size")
return parser.parse_args() 2. If the — data-uri parameter is a link to a file in a bucket, you need to download it:
filename = args.data_uri
if 'gs://' in filename:
new_filename = 'gs_file.csv'
scheme, bucket_name, path, file = process_gcs_uri(args.model_dir)
file_path = filename.split('//')[1].split('/', maxsplit=1)[1]
from google.cloud import storage
storage_client = storage.Client()
bucket = storage_client.get_bucket(bucket_name)
blob = bucket.blob(path)
blob.download_to_filename(new_filename)
filename = new_filename 3. Gcs uri parsing code:
def process_gcs_uri(uri: str) -> (str, str, str, str): '''
Receives a Google Cloud Storage (GCS) uri and breaks it down to the scheme, bucket, path and file Parameters:
uri (str): GCS uri Returns:
scheme (str): uri scheme
bucket (str): uri bucket
path (str): uri path
file (str): uri file '''
url_arr = uri.split("/")
if "." not in url_arr[-1]:
file = ""
else:
file = url_arr.pop()
scheme = url_arr[0]
bucket = url_arr[2]
path = "/".join(url_arr[3:])
path = path[:-1] if path.endswith("/") else path
return scheme, bucket, path, file 4. To log learning results in tensorboard, you need to set the path from the environment variable ‘AIP_TENSORBOARD_LOG_DIR’:
tensorboard_callback = tf.keras.callbacks.TensorBoard( log_dir=os.environ['AIP_TENSORBOARD_LOG_DIR'],histogram_freq=1)
or
from torch.utils.tensorboard import SummaryWriter writer = SummaryWriter(os.environ['AIP_TENSORBOARD_LOG_DIR'])
5. Upload the model files to Cloud Storage by a tensorflow model example:
tf_model.save_weights("best_model.h5")
scheme, bucket, path, file = process_gcs_uri(args.model_dir)
storage_client = storage.Client()
bucket = storage_client.bucket(bucket)
blob = bucket.blob(f"{path}/{args.model_name}.h5")
blob.upload_from_filename('best_model.h5') 6. As a result, we have the following training code:
def main():
# parse args
args = get_args()
# download dataset
filename = args.data_uri
if 'gs://' in filename:
new_filename = 'gs_file.csv'
scheme, bucket_name, path, file = process_gcs_uri(args.model_dir)
file_path = filename.split('//')[1].split('/', maxsplit=1)[1]
from google.cloud import storage
storage_client = storage.Client()
bucket = storage_client.get_bucket(bucket_name)
blob = bucket.blob(path)
blob.download_to_filename(new_filename)
filename = new_filename
N_EPOCHS = args.num_epochs
BATCHSIZE = args.batch
# train model
model = train_bert_sentiment(data_path=filename)
# save model
save_model(best_model, args.model_dir, args.model_name) The model training code now needs to be packed into a Docker container. To do this, let’s create a Dockerfile. As a base image, we use a ready-made image from the Google Cloud list containing the desired version of the framework and other necessary dependencies:
FROM us-docker.pkg.dev/vertex-ai/training/pytorch-gpu.1-9:latest WORKDIR /component RUN pip install transformers==3.0.2 tqdm COPY gpt_model.py . COPY transformers_utils.py . ENTRYPOINT ["python", "gpt_model.py"]
It is important to set the ENTRYPOINT in the format exactly as in the example, as this will allow you to set arguments for training.
Now let’s assemble the container with a tag in the format gcr.io/project_name/image_name:
docker build -f Dockerfile_train_text_model -t gcr.io/gems-ai-ml/pytorch_gpu_train_text .
Then send the container to the Container Registry:
docker push gcr.io/gems-ai-ml/pytorch_gpu_train_text
You can now train the model in Vertex AI. To do this, go to the Training tab and create a new custom job using the Create button.
Next, we set the name of the model.
Select a custom container and specify the previously downloaded image. We also need to define the training parameters.
Next, specify the Compute settings to run the container. (There are no GPU quotas for custom training by default, so you may need to write to a support team to increase quotas.)
Click Start training. Once training is complete, we see the Training pipeline with the Finished status.
You can view the details of the created pipeline by clicking its name. There you’ll find information about the training execution time, training arguments and machine parameters. You can also view logs and graphs for CPU and GPU utilization:
To view a Vertex AI TensorBoard associated with a training job:
- In the Vertex AI section of the Google Cloud console, navigate to the Training page
- Select the Custom Jobs tab
- To view the Training Detail page, select the training job
- At the top of the page, click the Open TensorBoard button
You can also create a Custom Job using the Python SDK:
from google.cloud import aiplatform
PROJECT_ID='gems-ai-ml'
BUCKET_NAME='gems-ai-ml-vertex'
APP_NAME=’gpt’aiplatform.init(project=PROJECT_ID, staging_bucket=BUCKET_NAME)# define variable names
CUSTOM_TRAIN_IMAGE_URI = f"gcr.io/{PROJECT_ID}/pytorch_gpu_train_text"
TIMESTAMP = datetime.now().strftime("%Y%m%d%H%M%S")
JOB_NAME = f"{APP_NAME}-text-model"# configure the job with container image spec
job = aiplatform.CustomContainerTrainingJob(
display_name=f"{JOB_NAME}",
container_uri=f {CUSTOM_TRAIN_IMAGE_URI}"
)# define training code arguments
training_args = ["--model-name=gpt-news-classifier", "--batch=54",
"--data-uri=gs://gems-ai-ml- vertex/datasets/bert_main_dataset_11k_news.csv",
"--model_dir=gs://gems-ai-ml-vertex/models"]# submit the Custom Job to Vertex Training service
model = job.run(
replica_count=1,
machine_type="n1-standard-8",
accelerator_type="NVIDIA_TESLA_T4",
accelerator_count=1,
args=training_args,
sync=False) As a result of training, we have a Tensorboard log and the model weights by the path specified in Cloud Storage. Custom Training made it possible to flexibly create a model training code, as well as take advantage of creating a Compute Engine with the required number of GPUs.
Deploy model
To deploy the model, you need to prepare the request processing code. You can use TorchServe as recommended in the Google documentation, but for simplicity and versatility, consider a flask application:
import argparse
import traceback
import torch
import numpy as np
from flask import Response, request, jsonify, Flask
from flask_cors import CORS
from transformers import GPT2Model, GPT2Tokenizerapp = Flask(__name__)
CORS(app)def load_model(model_path):
if 'gs://' in model_path:
new_filename = 'text_model.pth'
bucket_name = model_path.split('//')[1].split('/')[0]
file_path = model_path.split('//')[1].split('/', maxsplit=1)[1]
from google.cloud import storage storage_client = storage.Client(bucket_name)
bucket = storage_client.get_bucket(bucket_name)
blob = bucket.blob(file_path)
blob.download_to_filename(new_filename)
# download
model_path = new_filename
gpt = GPT2Model.from_pretrained('gpt2')
model = GPT2LinearSentiment(gpt)
model.load_state_dict(torch.load(model_path))
return model@app.route("/isalive")
def is_alive():
status_code = Response(status=200)
return status_code@app.route("/predict", methods=["POST"])
def predict():
global model
req_json = request.get_json()
news = req_json['instances']["news"]
preds = gpt_compute_sentiment(news, model =model)
return jsonify({
"predictions": preds.tolist()def get_args():
parser = argparse.ArgumentParser()
parser.add_argument(
'--model-path',
default="text_model.pth",
help='The name of your saved model')
return parser.parse_args()if __name__ == "__main__":
args = get_args()
model_path = args.model_path
app.run(debug=True, host="0.0.0.0", port=8080) In the code above, some points are omitted for brevity, but the most important details are preserved:
- Creating a flask application and adding CORS to avoid errors; No ‘Access-Control-Allow-Origin’.
- The loading code can be load_model’ed from Cloud Storage.
- Two mandatory routes: “/isalive” (ping that the server is running) and “/predict” (directly processing users’ request).
- Getting get_args command line arguments. The path to the weights of the model will be obtained through the command line parameters.
- Launching the app with the host address and port.
Now the model deployment code needs to be packed into a Docker container. To do this, let’s create a Dockerfile:
FROM us-docker.pkg.dev/vertex-ai/training/pytorch-gpu.1-9:latest WORKDIR /component RUN pip install transformers==3.0.2 tqdm flask flask-corsCOPY gpt_model.py . COPY transformers_utils.py . COPY deploy_text_model.py .EXPOSE 8080 ENTRYPOINT ["python", "deploy_text_model.py"]
Build a Docker image and upload it to the Container Registry.
On the Model Registry tab, import our model.
We set the name and select the region.
Select the container with the model and set the arguments.
Specify the routes and port inside the container, and click import.
Now we will create an Endpoint on the appropriate tab to test the added model.
Select the model created earlier and specify the Compute settings.
Also turn on monitoring and click Create.
After deploying the model to Endpoint, we will check its operability using Python SDK:
from typing import Dict, List, Union
from google.cloud import aiplatform
from google.protobuf import json_format
from google.protobuf.struct_pb2 import Valuedef predict_custom_trained_model_sample(
project: str,
endpoint_id: str,
instances: Union[Dict, List[Dict]],
location: str = "us-central1",
api_endpoint: str = "us-central1-aiplatform.googleapis.com",
): """
`instances` can be either single instance of type dict or a list of instances. """
# The AI Platform services require regional API endpoints.
client_options = {"api_endpoint": api_endpoint} # Initialize client that will be used to create and send requests.
# This client only needs to be created once, and can be reused for multiple requests. client = aiplatform.gapic.PredictionServiceClient(client_options=client_options) # The format of each instance should conform to the deployed model's prediction input schema. instances = instances if type(instances) == list else [instances]
instances = [
json_format.ParseDict(instance_dict, Value()) for instance_dict in instances
]
parameters_dict = {}
parameters = json_format.ParseDict(parameters_dict, Value())
endpoint = client.endpoint_path(
project=project, location=location, endpoint=endpoint_id
)
response = client.predict(
endpoint=endpoint, instances=instances, parameters=parameters
)
print("response")
print(" deployed_model_id:", response.deployed_model_id) # The predictions are a google.protobuf.Value representation of the model's predictions. predictions = response.predictions
for prediction in predictions:
print(" prediction:", dict(prediction))predict_custom_trained_model_sample(
project="38068****5047",
endpoint_id="662337******5424128",
location="us-central1",
instances={"news": "test news, sell all your stuff"}
) Finally, we have successfully deployed our model. You can monitor the workload of the Endpoint and Vertex AI will dynamically increase the number of Endpoints when the load increases.
Conclusion
In this article, we have talked about the key points of custom learning in Vertex AI. This platform contains all the necessary components for MLOps. It is also worth paying attention to AutoML which allows you to obtain a machine learning model without specific deep knowledge.
We also need to mention that at the operation stage there were also disadvantages, mainly related to versioning. You can create a dataset entity only if your file matches the desired schema, otherwise you must store it in cloud storage. Custom models are stored as a container, which makes it a bit difficult to add a new version for them.


Arthur Shaikhatarov
![]()
Arthur has served as project manager specializing in AI/ML initiatives at Zoreza Global for 4 years. His journey in artificial intelligence and machine learning began as an engineer, where he honed his skills and knowledge. Arthur is responsible for team management and formation, presales activities for ML projects, the orchestration and execution of AI/ML proofs-of-concept and the growth of AI/ML activities within Zoreza Global.





